
In today’s Technology world, staying up to date with all the new trends and technologies is extremely hard. This also includes native browsers Apis. One such technology that has been making waves in recent times is the SpeechRecognition Web API. This API allows developers to integrate speech recognition capabilities seamlessly into web applications, opening up…
How to make fluid typography with CSS
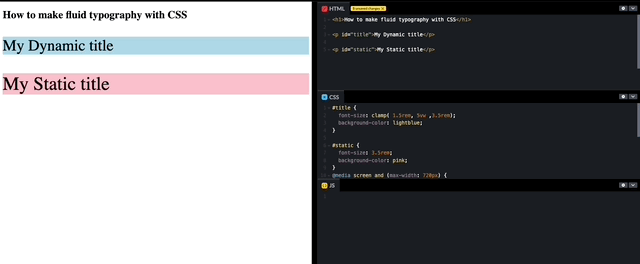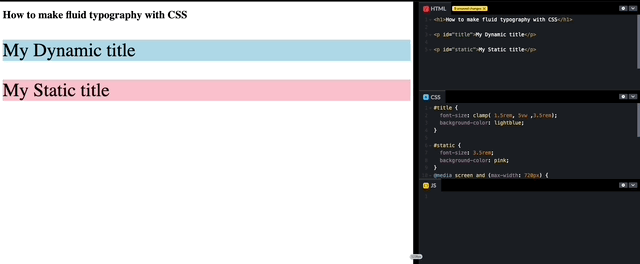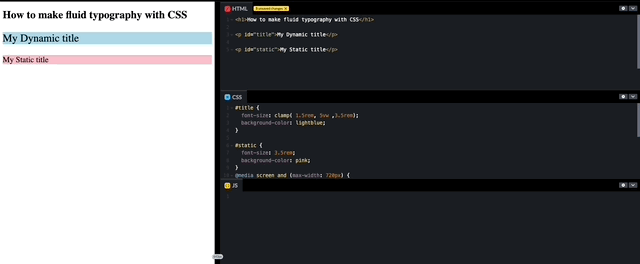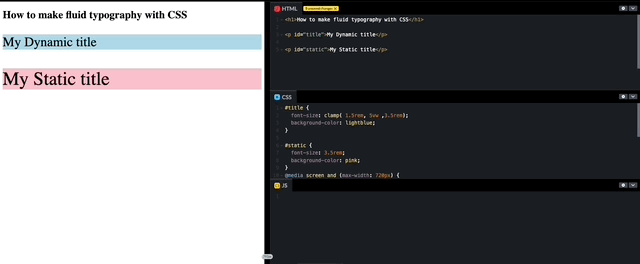
I have been developing for over a decade and creating Dynamic “font-size” has always been a long-discussed requirement. Until now, this feature was always achieved with the use of Javascript to support the font to scale up and down to fit within the container. Luckily for us, with the advances in CSS, we are actually…
How to wait for an element to render in the DOM

If you are reading this article, chances are you are looking for a way to trigger some code when an element becomes available on the page. This has been possible for a long time using hacks such as setTimeout or third libraries (usually built on top of setTimeout anyway). In this article, we are going…
How to use Teleport in VueJs 3

It has been a few months now since VueJs 3 has become the current version of this fantastic framework and with it, lots of new features. In this post, we will cover a feature called <teleport>. This feature was previously available in Vue 2 in a plugin called “portal-vue“. Thorsten Lünborg a core contributor of…
How to mock a server request in Chrome

If you are reading this article, then you probably have the same needs that I had when I first searched for this solution. I have decided to write this article to simplify your search and to write down the simple steps required to mock a server or API request in Chrome. TLTR; Chrome has the…